
티스토리 뷰
'기억보단 기억을' 블로그를 참고하여 작성하였습니다. 해당 프로젝트는 Java로 작성되어있으나 필자는 Kotlin 방식으로 작성하였습니다.
1. 프로젝트 생성
start.spring.io를 통해 생성
- Kotlin
- Gradle
- Spring Boot 2.7.1
- Java 17
라이브러리
- spring data jpa
- spring batch
- h2 DB
- lombok
- mysql
이렇게 애플리케이션을 생성하면 아래와 같은 build.gradle 파일이 생성된다.
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
plugins {
id("org.springframework.boot") version "2.7.1"
id("io.spring.dependency-management") version "1.0.11.RELEASE"
kotlin("jvm") version "1.6.21"
kotlin("plugin.spring") version "1.6.21"
}
group = "batch"
version = "0.0.1-SNAPSHOT"
java.sourceCompatibility = JavaVersion.VERSION_17
repositories {
mavenCentral()
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter-batch")
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
implementation("com.h2database:h2")
implementation("mysql:mysql-connector-java")
implementation("org.projectlombok:lombok")
implementation("org.jetbrains.kotlin:kotlin-reflect")
implementation("org.jetbrains.kotlin:kotlin-stdlib-jdk8")
testImplementation("org.springframework.boot:spring-boot-starter-test")
testImplementation("org.springframework.batch:spring-batch-test")
}
tasks.withType<KotlinCompile> {
kotlinOptions {
freeCompilerArgs = listOf("-Xjsr305=strict")
jvmTarget = "17"
}
}
tasks.withType<Test> {
useJUnitPlatform()
}애플리케이션을 열어보면 아래와 같은 `main 메소드`를 확인할 수 있다.
Main 메소드

해당 애플리케이션 위에 스프링 배치 기능 활성화를 위해 `@EnableBatchProcessing`을 추가해주자.
2. Spring Batch Job 생성
이렇게 배치 기능을 사용할 수 있게 세팅을 마쳤으면 job 패키지를 생성하고, SimpleJobConfiguration.class를 생성한다.

@Configuration
class SimpleJobConfiguration(
val jobBuilderFactory: JobBuilderFactory,
val stepBuilderFactory: StepBuilderFactory,
val simpleTasklet: SimpleTasklet
) {
val log = LoggerFactory.getLogger(this.javaClass.simpleName)
@Bean
fun simpleJob(): Job {
return jobBuilderFactory.get("simpleJob")
.start(simpleStep1())
.next(simpleStep2())
.build()
}
@Bean
fun simpleStep1(): Step {
return stepBuilderFactory.get("simpleStep1")
.tasklet { contribution, chunkContext ->
log.info(">> This is simpleStep1 <<")
RepeatStatus.FINISHED
}
.build()
}
@Bean
fun simpleStep2(): Step {
return stepBuilderFactory.get("simpleStep2")
.tasklet(simpleTasklet)
.build()
}
}@Component
@StepScope
class SimpleTasklet(): Tasklet {
val logger = LoggerFactory.getLogger(this.javaClass.simpleName)
override fun execute(contribution: StepContribution, chunkContext: ChunkContext): RepeatStatus? {
logger.info(">> This is simpleStep2 <<")
return RepeatStatus.FINISHED
}
}- @Configuration
- Spring Batch의 모든 Job은 `@Configuration`으로 등록해서 사용한다.
- jobBuilderFactory.get("simpleJob")
- `simpleJob`이란 이름의 batch Job을 생성한다.
- Job은 builder를 통해 이름으로 지정한다.
- stepBuilderFactory.get("simpleStep1")
- `simpleStep1`이란 이름의 BatchStep을 생성한다.
- step 또한 builder를 통해 이름으로 지정한다.
- tasklet { contribution, chunkContext -> ... } == tasklet { _, _ -> ... }
- step안에 수행될 기능들을 명시한다.
- Tasklet은 Step안에서 단일로 수행될 커스텀한 기능들을 선언할 때 사용한다.
- 여기서는 batch가 실행되면 `">> This is simpleStep1 <<"`를 출력하도록 했다.
Batch Job을 생성하는 simpleJob() 함수가 simpleStep1()을 품고 있는것을 볼 수 있다.
Spring Batch에서 Job은 하나의 배치 작업 단위를 애기하는데,
Job안에는 아래처럼 여러개의 Step이 존재하고 Step 안에 Tasklet 또는 Reader & Processor(optional) & Writer 묶음이 존재한다.

Job안에 여러 Step이 있는건 자연스럽지만, Step안에 존재하는 단위들은 애매하게 보일 수 있다.
Tasklet 하나와 Reader + Processor + Writer 한 묶음이 같은 레벨이다. 그래서 Reader & Processor가 끝나고 Tasklet으로 마무리하는 혼합 방식으로는 구현할 수 없다는걸 알고 있어야 한다.
Tasklet은 명확한 역할은 없지만 개발자가 지정한 커스텀한 기능을 위한 단위로 보면 되겠다.
그럼 이제 위에서 작성한 애플리케이션을 실행해보자.

로그가 찍힌것을 확인할 수 있다.
3. My SQL 환경에서 Spring Batch 실행
Spring Batch에서는 메타 데이터 테이블들이 필요하다. 이 테이블에는 아래와 같은 데이터를 갖고 있는다.
- 이전에 실행한 Job이 어떤것들이 있는지
- 최근에 실패한 Batch Parameter가 어떤것들이고, 성공한 Job은 어떤것들이 있는지
- 다시 실행한다면 어디서 부터 실행하면 되는지
- 어떤 Job에 어떤 Step들이 있었고, Step들 중 성공한것과 실패한 것들은 어떤것들인지
등 Batch 애플리케이션을 운영하기 위한 Metadata들이 여러 테이블에 나뉘어서 존재하게 된다.
아래는 메타 데이터 테이블 구조이다.

이 테이블들이 있어야만 Spring Batch가 정상적으로 작동하게 된다.
기본적으로 H2 DB를 사용할 경우엔 해당 테이블을 Boot가 실행 될 때 자동으로 생성해주지만, MySQL이나 Oracle과 같은 DB를 사용할 때는 개발자가 직접 생성해줘야 한다.
이 테이블들의 스키마는 이미 스프링 배치에 존재하고 이를 복사해서 create table만 해주면 된다.
본인의 IDE에서 파일 검색으로 schema-를 해보면 메타 테이블들의 스키마가 DBMS에 맞춰 각각 존재하는것을 볼 수 있다.

이제 MySQL을 이용해서 스프링 배치를 실행시켜 보겠다.
3-1. MySQL에 연결하기
application.yml 파일을 작성해서 연결할 DB 정보를 작성하자.
spring:
profiles:
active: local
---
spring:
config:
activate:
on-profile: local
datasource:
hikari:
jdbc-url: jdbc:h2:tcp://localhost:9092/~/h2db/batch
username: sa
password:
driver-class-name: org.H2.Driver
---
spring:
config:
activate:
on-profile: mysql
datasource:
hikari:
jdbc-url: jdbc:mysql://localhost:3306/batch
username: root
password: <password>
driver-class-name: com.mysql.jdbc.Driveractive 할 프로필이 local 이면 H2를 mysql 이면 MySQL을 사용하게 될 것이다.
- 스프링 부트의 경우 기본 Datasource는 HikariCP이다.
- jdbc-url : 연결할 DB 주소를 작성한다.
- username, password : 실제 자신이 db를 접속할 때 사용하는 것으로 기입한다.
- 각 db에 맞춰 드라이버를 지정해준다.
연결해 놓은 H2 DB와 MySQL
3-2. My SQL 환경으로 실행하기
mySql은 기본적으로 스프링 배치 메타 테이블이 생성되지 않는다고 했으니 mysql db로 돌리면 실패해야 할 것이다.
mysql 용 설정을 생성

실행

결과

Caused by: org.springframework.jdbc.UncategorizedSQLException: PreparedStatementCallback; uncategorized SQLException for SQL [SELECT JOB_INSTANCE_ID, JOB_NAME from BATCH_JOB_INSTANCE where JOB_NAME = ? and JOB_KEY = ?]; SQL state [3D000]; error code [1046]; No database selected; nested exception is java.sql.SQLException: No database selected
at org.springframework.jdbc.core.JdbcTemplate.translateException(JdbcTemplate.java:1542) ~[spring-jdbc-5.3.21.jar:5.3.21]실제로 해당 테이블이 없어서 오류가 나는것을 확인할 수 있다. 이제 메타 데이터 테이블을 생성해서 오류가 나지 않도록 해보자.

생성된 테이블 확인
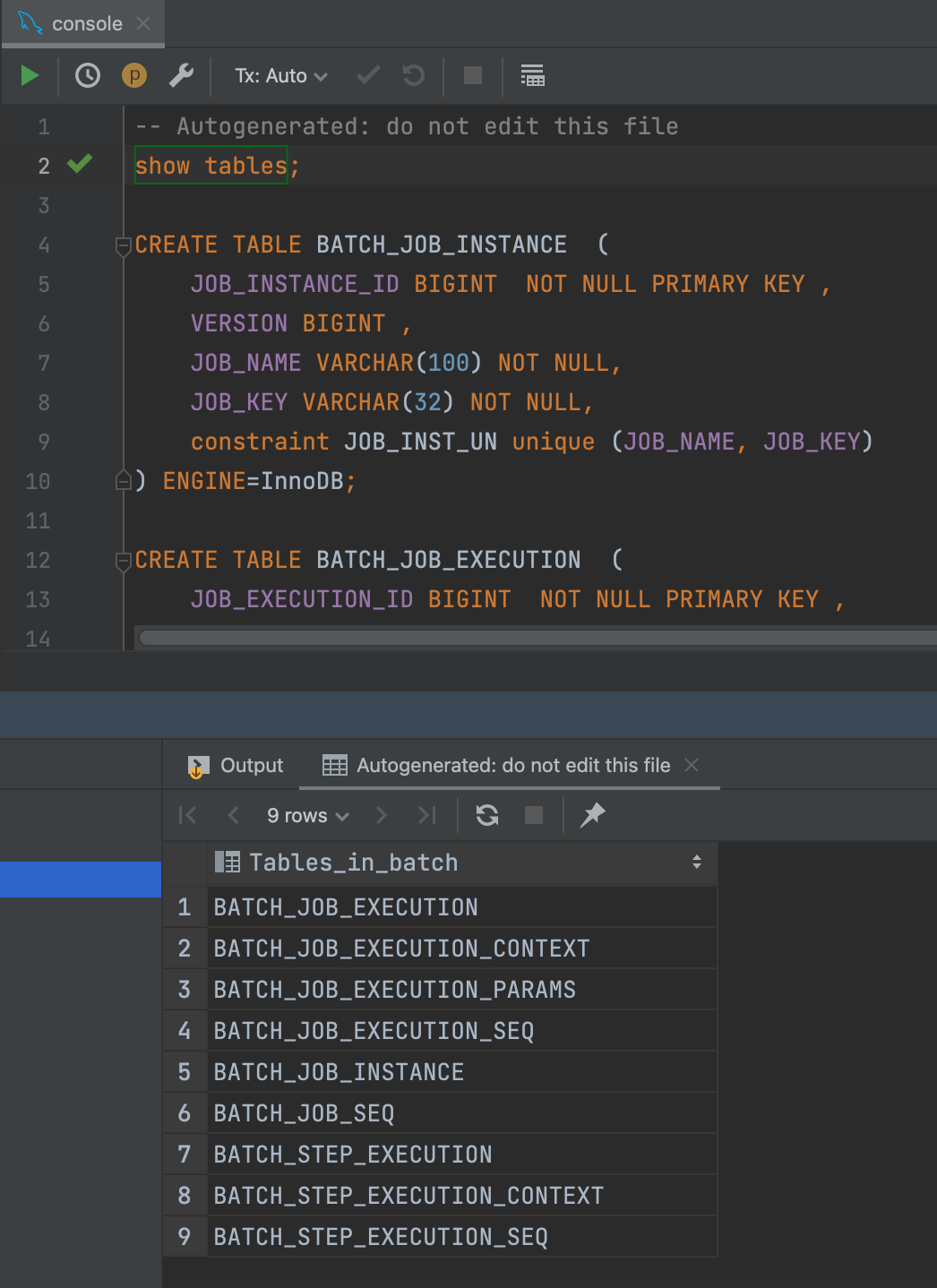
테이블이 생성되었으니 다시 Batch를 실행시켜보자.

성공적으로 MySQL DB와 연결해서 Batch를 실행시켰다. 이제 다음 챕터에서 이 메타 데이터 테이블을 확인해보며 의미하는 것들에 대해 알아보겠다.
'스프링 > 스프링 배치' 카테고리의 다른 글
| 2. 스프링 배치 가이드 with Kotlin - 메타 테이블 살펴보기 (0) | 2022.06.27 |
|---|

- Total
- Today
- Yesterday