Redis Cluster를 사용하면서 Lettuce 클라이언트의 Topology Refresh 설정을 빠뜨리는 경우가 생각보다 많다. 이번 글에서는 Redis Cluster에서 클라이언트가 어떻게 올바른 노드를 찾아가는지, 토폴로지가 outdated되면 어떤 장애가 발생하는지, 그리고 Lettuce가 제공하는 두 가지 갱신 전략의 동작 원리를 알아본다.
1. Redis Cluster 슬롯 구조 및 클라이언트 동작
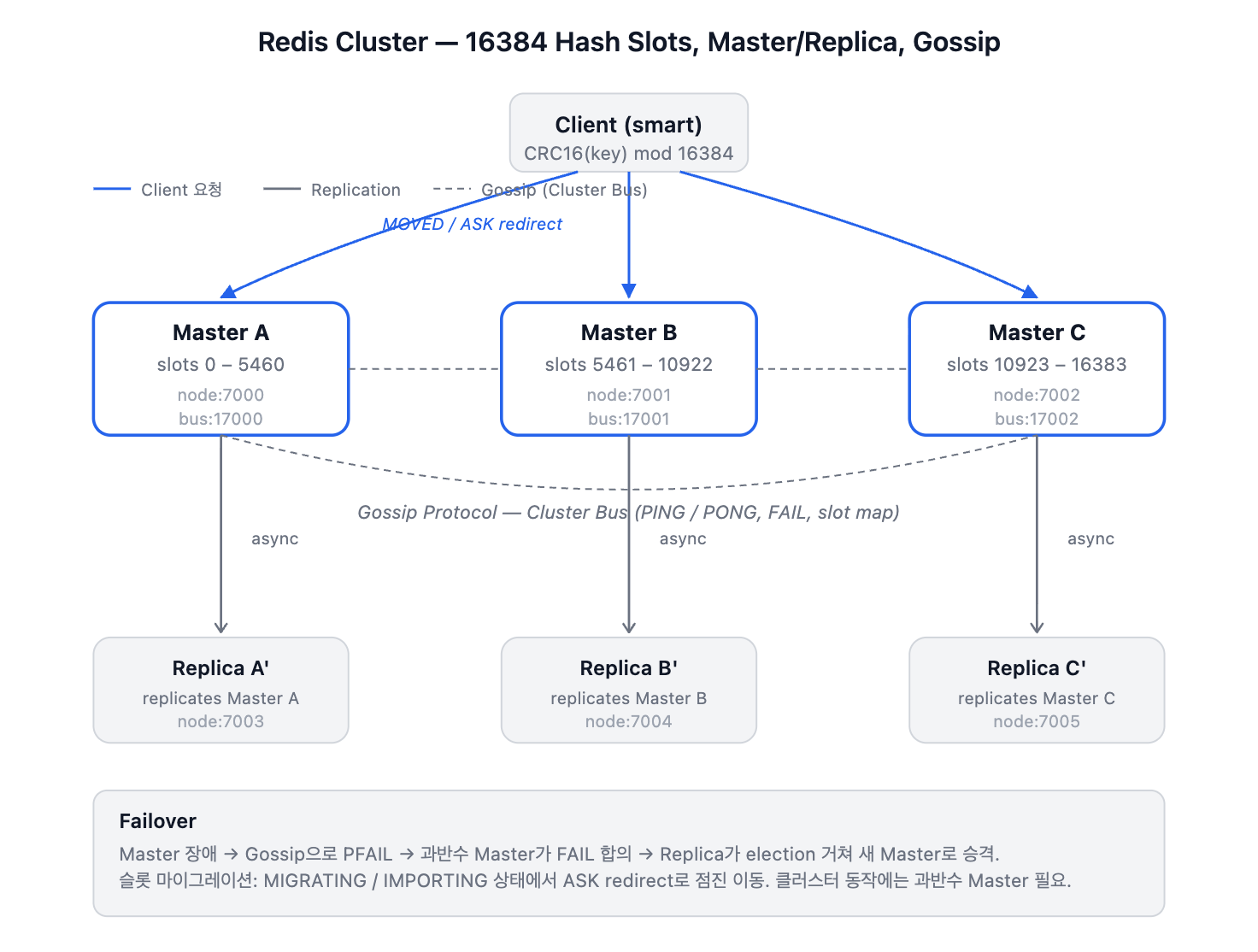
1. 해시 슬롯 기반 분산 구조
Redis Cluster는 전체 키 공간을 16,384개의 해시 슬롯(0~16383)으로 나누고, 각 Primary 노드가 이 슬롯의 일부를 담당한다.
클라이언트가 특정 키에 대한 명령을 보내면, CRC16(Key) % 16384 연산으로 슬롯 번호를 결정하고, 해당 슬롯을 담당하는 노드에 요청을 보내야 한다.
[3노드 Cluster 예시]
Primary A → 슬롯 0 ~ 5460
Primary B → 슬롯 5461 ~ 10922
Primary C → 슬롯 10923 ~ 16383
2. 프록시가 없는 아키텍처
여기서 중요한 점은 Redis Cluster에는 프록시 계층이 없다는 것이다. 노드 사이에서 요청을 대신 전달해주는 중간자가 없다. 만약 클라이언트가 슬롯 3999에 대한 요청을 Primary C에 보냈다면, Primary C는 이 요청을 Primary A로 전달해주지 않는다. 대신 MOVED 리다이렉션을 응답한다.
MOVED 3999 127.0.0.1:6379
"이 슬롯(3999)은 내가 아니라 127.0.0.1:6379가 담당하고 있으니 거기로 가라"는 길 안내인 셈.
3. Client (Smart)
그렇다면 클라이언트가 매번 아무 노드에나 요청을 보내고, MOVED를 받고, 다시 올바른 노드에 요청을 보내야 할까? 그러면 대부분의 요청이 2번의 네트워크 왕복(round trip)을 거치게 된다.
이 비효율을 해결하기 위해 Lettuce 같은 클라이언트는 슬롯-노드 매핑 정보를 로컬에 캐싱한다.
Lettuce는 처음 Redis Cluster에 연결할 때 CLUSTER SLOTS 또는 CLUSTER NODES 명령을 호출해서 전체 매핑 정보를 한 번 가져온다. 이후 요청부터는 이 로컬 매핑(이걸 Partition Table, 또는 Topology라고 부름)을 참조해서 직접 올바른 노드에 요청을 보낸다. 이런 방식의 클라이언트를 "Smart Client"라고 부른다.
[Smart Client 동작 흐름]
1) 최초 연결 시
Lettuce ──[CLUSTER SLOTS (명령어)]──→ Redis Cluster
Lettuce ←── 슬롯 매핑 정보 ── Redis Cluster
2) 이후 요청
GET user:123 → CRC16("user:123") % 16384 = 3999
→ 로컬 토폴로지 조회: 슬롯 3999 = Primary A
→ Primary A에 직접 요청 (1회 왕복)2. 토폴로지가 outdated되면 어떤 일이 벌어질까?
Smart Client가 로컬에 토폴로지를 캐싱하는 구조에는 한 가지 본질적인 문제가 있다. 클러스터 구성이 변경되면 로컬 토폴로지와 실제 상태 사이에 불일치가 발생한다는 것이다.
1. 클러스터 구성이 변경되는 세 가지 상황
- Failover
Primary가 죽고 Replica가 새 Primary로 승격된다.
이때 슬롯 range는 그대로 유지되고, 해당 슬롯을 담당하는 노드의 주소(IP:Port)만 변경된다. - Scale-out/in
새 노드가 추가되거나 기존 노드가 제거된다.
기존 노드가 가진 슬롯 중 일부를 떼어서 새 노드에 넘기는 Slot Migration 과정을 거친다.
이 과정에서 슬롯이 이동 중인 상태가 생기고, ASK 리다이렉션이 발생한다. - 노드 교체
유지보수 등으로 노드의 IP 자체가 변경된다.
2. MOVED로 복구되는 경우
구성 변경 후에도 요청을 받는 노드가 살아있다면, MOVED 리다이렉션을 통해 올바른 노드로 재요청할 수 있다. 레이턴시가 2배로 늘어나는 비효율은 생기지만, 최소한 요청 자체는 성공한다.
단, 100ms 내로 제공해야하는 저지연 API 서비스에서는 이러한 추가 왕복도 치명적일 수 있다.
3. 응답조차 받을 수 없는 경우 (진짜 문제)
Failover 상황이 심각한 이유는 따로 있다. Primary A가 죽었고, Replica A'가 승격된 상황을 생각해보자.
Q. Lettuce는 여전히 죽은 Primary A의 IP:Port를 토폴로지에 들고 있다. 이 경우 Lettuce가 죽은 노드에 요청을 보내면, MOVED 응답이 올까?
A. 올 수 없다. 죽은 노드이기 때문이다.
TCP 연결 자체가 실패하거나, 연결이 되더라도 응답이 오지 않아 커넥션 타임아웃이 발생한다. 그리고 이건 한 번의 타임아웃으로 끝나지 않는다. outdated 토폴로지에는 여전히 죽은 노드가 해당 슬롯의 담당자로 기록되어 있으니, 해당 슬롯 범위에 속하는 모든 키에 대한 요청이 계속 죽은 노드로 간다.
[클러스터 실제 상태]
Node A (죽음) → 슬롯 0~5460
Node A' (승격됨!) → 슬롯 0~5460 ← 여기로 가야 함
[Lettuce 로컬 토폴로지 - outdated]
Node A (IP:6379) → 슬롯 0~5460 ← 여전히 여기로 보냄
↓
timeout... timeout... timeout...
Replica A'가 이미 승격되어 정상 서비스 중인데도, 클라이언트만 그 사실을 모르는 것이다. 이것이 Topology Refresh가 필요한 핵심적인 이유다.
3. Topology Refresh _ 두 가지 갱신 전략
이 문제를 해결하려면 Lettuce가 클러스터 구성 변경을 감지하고 로컬 토폴로지를 갱신해야 한다.
Lettuce는 이를 위해 Periodic Topology Refresh와 Adaptive Topology Refresh 두 가지 전략을 제공한다.(Redis 공식 문서)
1. Periodic Topology Refresh _ 주기적 폴링
말 그대로 고정된 주기마다 CLUSTER SLOTS 명령을 호출해서 최신 토폴로지를 가져오는 방식이다.
디폴트 값은 60초이다.
장점: 클러스터에 어떤 변화가 발생하든 주기가 돌아오면 반영된다. Scale-out으로 노드가 추가되고 Slot Migration이 발생하는 것처럼 점진적인 변화를 점진적으로 반영하기에 적합하다.
단점: 주기 사이에 발생한 변화는 다음 주기까지 반영되지 않는다. 30초 주기로 설정했다면, 최악의 경우 30초 동안 outdated 토폴로지로 요청을 보내게 된다.
2. Adaptive Topology Refresh — 이상 신호 기반 갱신
주기적으로 폴링하는 대신, 클라이언트가 받는 비정상 응답을 트리거로 활용해서 토폴로지를 갱신하는 방식이다. Lettuce가 감지하는 트리거는 다음과 같다.
- MOVED 리다이렉션 — 슬롯 소유권이 바뀌었다는 신호
- ASK 리다이렉션 — Slot Migration이 진행 중이라는 신호
- PERSISTENT_RECONNECTS — 연결 끊김 후 재연결 시도가 반복되는 상황
- UNCOVERED_SLOT — 담당 노드가 없는 슬롯 발견
- UNKNOWN_NODE — 토폴로지에 없는 노드로부터 응답을 받은 경우
장점: 이벤트 발생 즉시 반응하므로 Periodic 방식보다 빠르게 복구할 수 있다.
단점: 첫 번째 에러는 불가피하다. MOVED나 타임아웃이 발생해야 비로소 갱신이 시작되기 때문이다.
3. Adaptive의 Debounce 메커니즘
장애 상황을 상상해보자.
- 커머스에 수십만 사용자들이 몰려들어왔고 수만가지 상품을 조회하고 있다. 이때 클러스터에 scale out이 발생해서 슬롯 마이그레이션이 발생하고 있다. 특정 상품을 들고 있는 마스터 노드가 변경되었으므로 기존 노드로 요청을 받은 마스터가 ASK 또는 MOVED를 답변하게 된다. 수천~수만의 요청이 발생하고 Adaptive Topololgy Refresh가 동작하게 된다. 이때 그러면 모든 비정상 응답에 대해 트리거가 동작하면서 Topolgy Refrsh를 하게 될까?
위 상황에서 트리거가 발생할 때마다 매번 CLUSTER SLOTS를 호출하면 갱신 요청이 폭주할 수 있다.
-> Lettuce는 바로 이런 상황을 Debounce 방식으로 방어한다.
첫 번째 트리거에서 바로 갱신을 실행하고, 갱신 후 일정 시간(timeout) 동안은 추가 트리거가 와도 무시한다. 이 조용한 기간이 지나면 다시 트리거에 반응할 수 있게 된다.
[Debounce 동작 흐름]
MOVED → 갱신 실행! → [조용한 기간 (timeout)] → MOVED → 갱신 실행! → ...
이 구간의 트리거는 무시또한 PERSISTENT_RECONNECTS 트리거에는 refreshTriggersReconnectAttempts 옵션을 설정할 수 있다.
예를 들어 값을 3으로 설정하면, 재연결 시도를 3번 했는데도 안 될 때 비로소 토폴로지 갱신을 트리거한다. 일시적 네트워크 이슈와 실제 노드 장애를 구분하기 위한 임계값이다.
(*참고로 HTTP에서 패킷 재전송을 위한 ACK 중복 수신 임계값은 3회이다.)
4. 둘 다 키는게 가장 권장된다
| Periodic | Adaptive | |
| 트리거 | 고정 주기 (예: 30초마다) | MOVED, ASK, 연결 끊김 등 |
| 장점 | 점진적 변화를 반영 | 장애 즉시 반응 |
| 단점 | 주기 사이 공백 존재 | 첫 에러는 불가피 |
| 폭주 방어 | 주기 자체가 방어 | Debounce |
| 적합한 상황 | Scale-out, Slot Migration | Failover, 노드 장애 |
둘은 상호 보완적이다. Periodic으로 평상시 변화를 꾸준히 반영하고, Adaptive로 갑작스러운 장애에 빠르게 대응한다.
실무에서는 두 가지를 모두 활성화하는 것이 권장된다.
4. Spring Boot 3.x + Lettuce 설정 코드
4-1. 설정 객체 생성 흐름
Topology Refresh를 Spring Boot에서 설정하려면, 아래 순서로 객체를 조립해서 LettuceConnectionFactory를 만들어야 한다.
ClusterTopologyRefreshOptions ← Topology Refresh 전략 설정
↓
ClusterClientOptions ← Lettuce 클라이언트 전체 옵션
↓
LettuceClientConfiguration ← Spring이 이해하는 클라이언트 설정
↓
LettuceConnectionFactory ← 최종 커넥션 팩토리 (+ RedisClusterConfiguration)4-2. 전체 설정 코드
@Configuration
public class RedisClusterConfig {
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
// 1. Topology Refresh 옵션
ClusterTopologyRefreshOptions topologyRefreshOptions = ClusterTopologyRefreshOptions.builder()
.enablePeriodicRefresh(Duration.ofSeconds(30)) // 30초마다 주기적 갱신
.enableAllAdaptiveRefreshTriggers() // 모든 Adaptive 트리거 활성화
.refreshTriggersReconnectAttempts(3) // 재연결 3회 실패 시 갱신
.build();
// 2. Cluster Client 옵션
ClusterClientOptions clientOptions = ClusterClientOptions.builder()
.topologyRefreshOptions(topologyRefreshOptions)
.build();
// 3. Lettuce Client Configuration
LettuceClientConfiguration clientConfig = LettuceClientConfiguration.builder()
.clientOptions(clientOptions)
.build();
// 4. Cluster 서버 설정 (ElastiCache Configuration Endpoint)
RedisClusterConfiguration serverConfig = new RedisClusterConfiguration(
List.of("clustercfg.my-cluster.xxxxx.apn2.cache.amazonaws.com:6379")
);
// 5. 조립
return new LettuceConnectionFactory(serverConfig, clientConfig);
}
}- enableAllAdaptiveRefreshTriggers()는 위에서 설명한 5가지 트리거를 한 번에 활성화하는 단축 메서드다.
- MOVED_REDIRECT, ASK_REDIRECT, PERSISTENT_RECONNECTS, UNCOVERED_SLOT, UNKNOWN_NODE
ElastiCache Cluster 모드에서는 Configuration Endpoint 하나만 넣어주면 나머지 노드 정보는 자동으로 디스커버리된다. RedisClusterConfiguration에 이 엔드포인트를 전달하는 것으로 서버 설정은 충분하다.
3. 주의사항: RedisClusterConfiguration vs RedisStaticMasterReplicaConfiguration
서버 설정 객체를 선택할 때 주의해야 할 점이 있다.
RedisStaticMasterReplicaConfiguration은 Master-Replica(Sentinel) 구조를 위한 설정 클래스다.
Cluster 모드에서는 반드시 RedisClusterConfiguration을 사용해야 한다.
5. Sentinel 모드에서는 왜 Topology Refresh가 필요 없을까?
Redis의 Master-Replica 구조에서 Sentinel을 사용하는 경우, 슬롯 기반 분산이 없으므로 ClusterTopologyRefreshOptions은 필요하지 않다. 하지만 Failover 시 클라이언트가 새 Master를 알아야 하는 문제는 동일하게 존재한다.
차이점은 토폴로지 관리의 책임 주체가 다르다는 것이다.
[Cluster 모드]
Client(Lettuce) ──CLUSTER SLOTS──→ Redis 노드들
→ 클라이언트가 직접 토폴로지를 관리
[Sentinel 모드]
Client(Lettuce) ──"현재 Master 누구?"──→ Sentinel
Sentinel ──Pub/Sub 알림──→ Client
→ Sentinel이 마스터 변경을 감지하고 클라이언트에게 push- Sentinel 모드에서는 Sentinel 프로세스가 Master 변경 이벤트를 Pub/Sub으로 클라이언트에 push해주기 때문에, 클라이언트가 스스로 폴링하거나 이상 신호를 감지할 필요가 없다.
- 토폴로지 관리를 Sentinel이 대신해주므로 클라이언트가 별도로 Refresh 전략을 구성할 필요가 없는 것이다.
| Cluster 모드 | Sentinel 모드 | |
| 라우팅 | 클라이언트가 슬롯 기반 직접 라우팅 | 단일 Master로 전부 전송 |
| 토폴로지 관리 주체 | 클라이언트 (Smart Client) | Sentinel 프로세스 |
| 갱신 방식 | Periodic + Adaptive Refresh | Sentinel Pub/Sub 알림 |
| 설정 | ClusterTopologyRefreshOptions | RedisSentinelConfiguration |
6. 정리
Redis Cluster는 프록시 없는 아키텍처이기 때문에, 클라이언트(Lettuce)가 슬롯-노드 매핑 정보(토폴로지)를 로컬에 캐싱하고 직접 올바른 노드에 라우팅하는 Smart Client 방식으로 동작한다.
문제는 클러스터 구성이 변경되었을 때 발생한다. 특히 Failover 상황에서 토폴로지를 갱신하지 않으면, 죽은 노드로 요청이 계속 전달되어 타임아웃이 발생하고, 해당 슬롯 범위 전체가 먹통이 되는 장애로 이어진다.
Lettuce는 이를 위해 두 가지 갱신 전략을 제공한다.
1. Periodic Topology Refresh는 고정 주기(권장 30초 이하)로 폴링하여 점진적 변화를 반영하고,
2. Adaptive Topology Refresh는 MOVED, ASK 리다이렉션이나 연결 끊김 같은 이상 신호를 트리거로 즉시 갱신한다.
실무에서는 두 가지를 모두 활성화하여 평상시 변화와 갑작스러운 장애 모두에 대응하는 것이 권장된다.
핵심 정리
Redis Cluster는 프록시가 없는 구조이므로, Lettuce 같은 Smart Client가 슬롯-노드 매핑 정보를 로컬에 캐싱해서 직접 올바른 노드에 라우팅한다. 하지만 Failover나 Scale-out으로 클러스터 구성이 변경되면 로컬 토폴로지와 실제 상태 사이에 불일치가 생기고, 특히 노드가 죽은 경우에는 MOVED 리다이렉션조차 받을 수 없어 해당 슬롯 범위 전체에서 타임아웃이 지속되는 장애가 발생한다. 이를 방지하기 위해 Lettuce는 Periodic Topology Refresh(주기적 폴링)와 Adaptive Topology Refresh(이상 신호 기반 즉시 갱신 {MOVED, ASK, 연결 끊김 등}) 두 가지 전략을 제공하며, 실무에서는 두 가지를 모두 활성화하여 점진적 변화와 급격한 장애 양쪽에 대응한다.
참고 자료
'기술 학습' 카테고리의 다른 글
| Hibernate Connection Release Mode 커넥션 관리 전략 _ JPA @Transactional (0) | 2026.04.25 |
|---|---|
| 분산 시스템 CAP 정리 (0) | 2026.03.31 |
| HTTP/1.1, HTTP/2, HTTP/3 프로토콜 비교 정리 (1) | 2026.03.31 |
| MSA에서 CORS 문제를 해결하는 4가지 전략 (0) | 2026.03.27 |
| TCP/IP 체크섬(Checksum) 내부 동작 원리 (0) | 2026.03.23 |