
티스토리 뷰
레포지토리
기본적으로 데이터를 DB에 저장하기 위해서 레포지토리 클래스가 존재한다. 직접 데이터베이스에 CRUD를 하는 계층이다. 다만, JPA를 사용하지 않았을 경우 직접 쿼리도 작성해야하고, 매개변수도 받아줘야 하는 불편함이 존재한다.
JPA를 사용하지 않는 경우 레포지토리
@Repository
public class BookRepo {
@PersistenceContext
EntityManager em;
public void save(Book book) {
em.persist(book);
}
public Book findByName(String name) {
return em.createQuery("select b from Book b where b.name = :name", Book.class)
.setParameter("name", name)
.getSingleResult();
}
public boolean existBookByName(String name) {
List<Book> books = em.createQuery("select b from Book b where b.name = :name", Book.class)
.setParameter("name", name)
.getResultList();
return !books.isEmpty();
}
}위와같이 필요한 메소드마다 쿼리를 작성해줘야 한다. 지금이야 파라미터가 하나거나 다른 테이블과 조인하는 부분도 없지만 그런 부분까지 추가된다면 가독성이 더욱 떨어지게 될것이다.
이러한 문제점들을 해결하기 위해 나온것이 Spring Data JPA이다.
Spring Data Jpa - JpaRepository
JPA는 인터페이스로 객체를 레포지토리에 기본적으로 CRUD 하는 인터페이스를 제공한다.
- findById, findAll, save, saveAll 등등
즉, 대부분의 엔티티에서 반복적으로 사용되는 단순 쿼리들을 Spring Data Jpa가 인터페이스 형태의 메소드로 만들어 놓고 Hibernate가 애플리케이션이 실행될 때 엔티티에 맞춰서 동적으로 구현해서 우리는 필요할 때 메소드만을 불러서 사용할 수 있게 해주는 것이다.
JPA를 통해 얻을 수 있는 것
- 기본적으로 제공되는 CRUD를 제공받을 수 있다.
- 엔티티의 원하는 필드값의 조합을 통해 인터페이스에 추가적으로 작성해서 바로 (구현없이) 사용할 수 있다.
- 페이징 기법을 사용할 수 있다. (채팅 목록, 게시물 등을 부분적으로 페이징 처리해서 가져오는 것)
- 직접 쿼리문을 작성하여 Fetch Join 등을 이용해서 조회하여 가져올 수 있다.
JPA를 사용하는 방법
- extends를 통해 JpaRepository<> 상속받고 <>안에 레포지토리에 연결할 엔티티 클래스명, 엔티티의 PK 자료형을 적어준다.
ex) JpaRepository<Member, Long>
JpaRepsitory 사용하기
Entity : Memer.class
PK : Long
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
Optional<Member> findBySeq(Long seq);
Optional<Member> findBySeqBefore(Long seq);
Optional<Member> findByEmail(String email);
Optional<Member> findByEmailAndActivateYn(String email);
Boolean existsByEmail(String email);
@Query("select m from Member m join fetch m.mypage join fetch m.authorizeUser where m.email=?1")
Optional<Member> findByEmailFJ(String email);
}- findBySeq, findByEmail, existByEmail
- 엔티티에 존재하는 컬럼값을 기반으로 사용자가 추가해서 만들 수 있다. 그러면 JPA는 알아서 해당 값을 기반으로 구현되어 작동된다.
- @Query("xxx")
- 쿼리문을 직접 작성해서 연관관계가 있는 테이블과 fetch join을해서 한 뭉텅이로 가져오도록 할 수 있다. 이때 메소드 명은 자유롭게 작성하면 된다.
- And, Or, After, Before 조합 등을 제공한다.
- And는 && 조건을 추가하는 것이다.
- Or는 || 조건을 추가하는 것이다.
- After는 값의 비교가 더 큰거를 찾는다.
- Before는 값의 비교가 더 작은것을 찾는다.
- 이 외에도 정말 많은 조건들이 존재하니 공식 문서를 참고해보자

@Query 작성 예시
쿼리를 작성해줄 때, 파라미터를 넘겨주는 방식에는 두가지가 존재한다.
- 위치기반으로 넘겨주기 (1번 파라미터, 2번 파라미터 등)
- 이름기반으로 넘겨주기 (bookName = ?, price = ? 등)
이때, 이름 기반으로 넘겨주는 것을 지향하라고 했는데 이유는 가독성 때문이다. 위치기반으로 넘기면 쿼리가 매개변수의 순서로 지칭되므로 쿼리를 봐도 다시 메소드의 파라미터를 확인해야 한다.
하지만 이름기반으로 넘기면 이미 쿼리에 이름이 들어가있으므로 직관적으로 이해할 수 있다.
Book Repo 인터페이스 (레포지토리)
@Repository
public interface BookRepo extends JpaRepository<Book, Long> {
@Query("select b from Book b where b.name like concat(:name, '%') and b.price > :price")
Optional<Book> findByNameStartingWithAndPriceAfter(
@Param("name") String startName,
@Param("price") Integer bookPrice
);
@Query("select b from Book b where b.name like concat('%', :name, '%') and b.price > :price")
Optional<Book> findByNameContainingAndPriceAfter(
@Param("name") String bookName,
@Param("price") Integer bookPrice
);
}- 1번
- 이름과 가격을 전달받고 해당 이름으로 시작하면서 그리고 그 가격 이상인 책을 찾는 쿼리이다.
- @Param("매개변수이름")을 통해 넘겨받는 파라미터의 이름을 통해 쿼리에 바인딩하고 있다.
- 2번
- 이름과 가격을 전달받고 해당 이름을 포함하고 그리고 그 가격 이상인 책을 찾는 쿼리이다.
- 똑같이 이름 기반으로 파라미터를 넘겨받고 있다.
테스트 및 결과
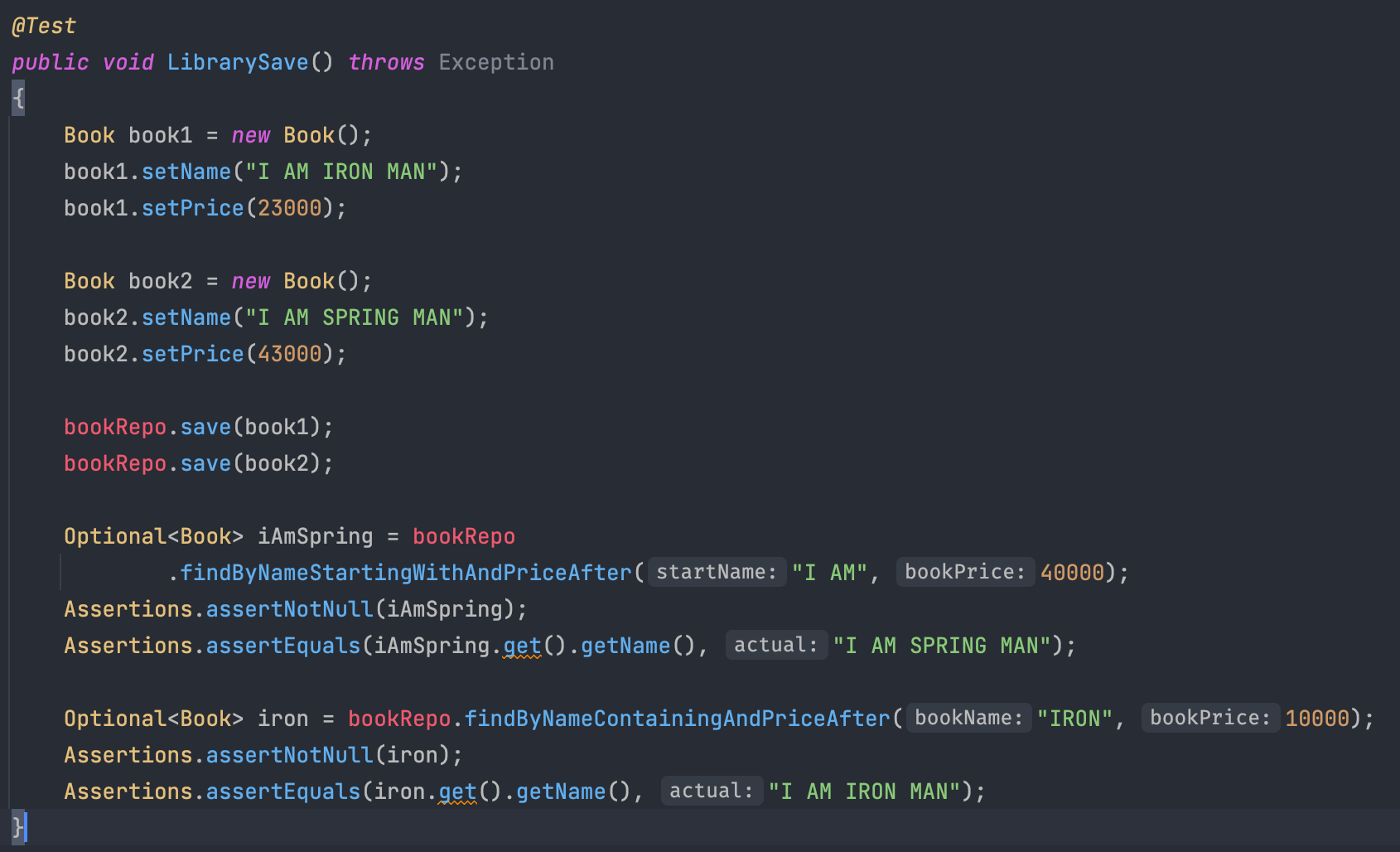
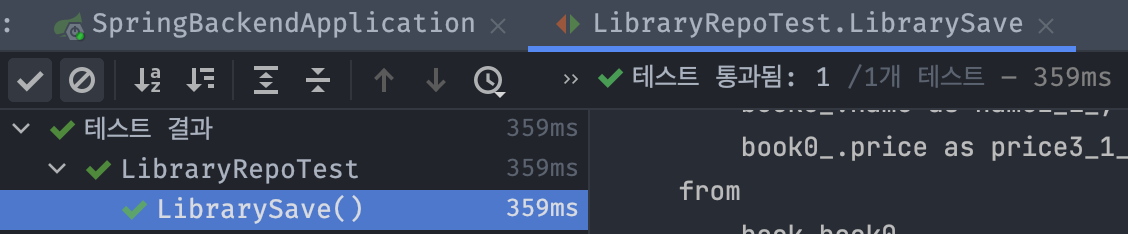
정상적으로 테스트가 통과된 것을 확인할 수 있다. 이런식으로 쉽고 편리하면서 활용도가 무궁무진한 Spring Data Jpa를 잘 사용해보자.
'스프링 > 스프링 JPA 정리 시리즈' 카테고리의 다른 글
| Spring Data JPA 정리 5 _ 페이징 & 정렬 (0) | 2022.03.18 |
|---|---|
| Spring Data JPA 정리 3 _ 연관관계 매핑 (일대일, 다대일, 일대다, 다대다) (1) | 2022.03.14 |
| Spring Data JPA 정리 2 _ 애노테이션 (0) | 2022.03.12 |
| Spring Data JPA 정리 1 _ 기본 및 개념 (0) | 2022.03.10 |



- Total
- Today
- Yesterday