카프카 스트림즈

카프카에서 공식적으로 지원하는 라이브러리로, 토픽에 적재된 데이터를 실시간으로 변환하여 다른 토픽에 적재하는 라이브러리이다. 스트림즈 애플리케이션 또는 카프카 브로커의 장애가 발생하더라도 Exactly Once를 보장할 수 있도록 장애 허용 시스템 (fault tolerant system)을 가지고 있어서 데이터 처리 안정성이 매우 뛰어나다. 만약 토픽에 있는 데이터를 실시간 스트림 처리 필요가 있다면 스트림즈 애플리케이션을 개발하는 것을 1순위로 고려하는 것이 좋다!
프로듀서와 컨슈머를 조합하지 않고 스트림즈를 사용하는 이유
스트림 데이터 처리에 있어 필요한 다양한 기능을 스트림즈 DSL로 제공하기 때문이다. 이에 필요한 프로세서 API를 사용하여 쉽게 코드로 구현이 가능하다는 장점이 있다. 또한, 컨슈머와 프로듀서만을 사용하여 어느정도 구현이 가능하겠지만 스트림즈 라이브러리에서 제공하는 Exactly Once 데이터 처리, 장애 허용 시스템 등의 특징들은 구현해내기가 매우 어렵다. 따라서 실시간 처리를 윈한다면 스트림즈를 사용하는 것이 좋다.
단, 사용하는 토픽(소스 토픽)과 저장하는 토픽(싱크 토픽)의 카프카 클러스터가 다른 경우는 스트림즈가 지원하지 않는다. 따라서 이때는 컨슈머 + 프로듀서 조합으로 직접 클러스터를 지정하는 방식으로 개발해야한다.
스트림즈 내부 구조

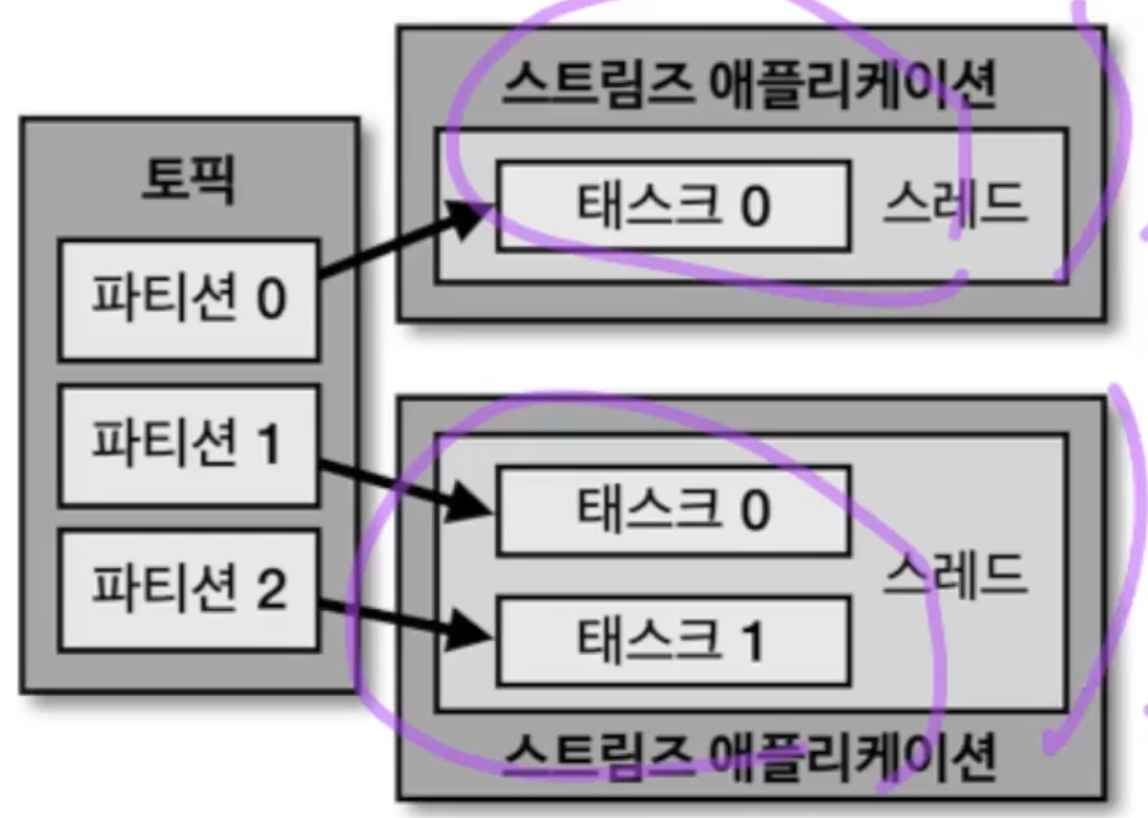
스트림즈 애플리케이션은 내부적으로 스레드를 1개 이상 생성할 수 있으며, 스레드는 1개 이상의 태스크를 갖는다. 스트림즈의 태스크는 스트림즈 애플리케이션을 실행하면 생기는 데이터 처리 최소 단위이다. 만약 3개의 파티션을 가진 토픽을 처리하는 스트림즈 앱이 실행된다면 3개의 태스크가 생기게 되는 것이다.
왼쪽 그림처럼 앱 내 하나의 스레드가 파티션과 태스크를 1 : 1 대응하여 생성하여 프로세싱 로직을 처리할 수 있으며, 스레드를 파티션 개수만큼 생성하여 병렬처리하는 방법도 가능하다. 두번째 그림의 경우 프로세스를 n개 만들어서 파티션을 처리하는 방법이다. 이 경우 장애가 발생하더라도 안정적으로 운영이 가능하도록 2개 이상의 스트림즈 애플리케이션 서버를 운영하는 것이다.
일반적으로 파티션 개수만큼 애플리케이션 프로세스를 운용하며 장애가 발생하더라도 failover되며 다른 스트림즈로 지속 처리가 가능하도록 하는 형태가 사용된다.
토폴로지

카프카 스트림즈의 구조와 사용방법을 알기 위해서는 토폴로지와 관련된 개념을 먼저 알아야 한다. 토폴리지는 2개 이상의 노드들과 선으로 이뤄진 집합을 뜻한다. 종류로 ring, tree, star 형이 존재하며 카프카 스트림즈에서 사용하는 토폴로지 경우 tree 형태와 유사하다.
소스 프로세서, 스트림 프로세서, 싱크 프로세서

소스 프로세서
- 하나 이상의 토픽에서 데이터를 가져오는 역할을 한다. 따라서 데이터를 처리하기 위해 최초로 선언해야하는 노드이다.
스트림 프로세서
- 다른 프로세서가 반환한 데이터를 처리하는 역할을 한다. 변환, 분기처리와 같은 로직이 데이터 처리의 일종이라고 볼 수 있다.
싱크 프로세서
- 변환된 데이터를 특정 카프카 토픽에 저장하는 역할을 한다. 스트림즈로 처리된 데이터의 마지막 최종 노드이다.
스트림즈DSL과 프로세서API
스트림즈DSL (Domain Specific Language)와 프로세서 API 2가지 방법으로 개발이 가능하다. 스트림즈DSL은 스트림 프로세싱에 쓰일만한 다양한 기능들을 자체 API로 만들어 놓았기 때문에 대부분의 변환 로직을 쉽게 개발할 수 있다. 하지만 특정 간격마다 처리하는 등 일부 기능들은 제공되지 않는데 이런 경우 프로세서 API를 사용하여 구현이 가능하다.
스트림즈 DSL로 구현하는 처리 예시
- 메시지 값을 기반으로 토픽 분기 처리
- 지난 10분간 들어온 데이터의 개수 집계
프로세서 API로 구현하는 처리 예시
- 메시지 값의 종류에 따라 토픽을 가변적으로 전송
- 일정한 시간 간격으로 데이터 처리
스트림즈 DSL
스트림즈 DSL에서 다루는 새로운 개념이 존재한다. 스트림즈 DSL은 레코드의 흐름을 추상화한 3가지 개념이 등장하는데 KStream, KTable, GlobalKTable 이 있다. 이 3가지 개념은 컨슈머, 프로듀서, 프로세서 API에서는 사용되지 않고 스트림즈 DSL에서만 사용되는 개념이다.
KStream

- 레코드의 흐름을 표현한다.
- 레코드는 하나씩, 들어오는대로 하나씩 키값 쌍으로 처리하게 된다.
- 메시지 키와 메시지 값으로 구성되어 있다.
- KStream으로 조회하면 토픽에 존재하는 (or KStream에 존재하는) 모든 레코드가 출력된다.
- KStream은 컨슈머로 토픽을 구독하는 것과 동일한 선상에서 사용하는 것이다.
KTable

- 레코드의 최신 상태를 표현한다.
- KSteam과 다르게 메시지 키를 기준으로 묶어서 사용한다. 마치 HashTable 마냥.
- KStream은 토픽의 모든 레코드를 조회할 수 있지만, KTable은 unique한 메시지 키를 기준으로 latest 레코드를 사용하게 된다.
- KTable로 데이터를 조회하면 메시지 키를 기준으로 가장 최신 데이터만 출력된다.
- 새로 데이터를 적재하는데 이미 키가 있다면 데이터가 업데이트 되는 것이다.
- 최신 데이터만 가지는 주소와 같은 형태에서 사용할 수 있을 것이다.
코파티셔닝

KStream과 KTable 데이터를 조인한다고 가정하자. 이때 반드시 서로 co-partitioning (코 파티셔닝) 되어있어야 가능하다. 코파티셔닝이란 조인을 하는 2개 데이터의 파티션 개수가 동일하고 파티셔닝 전략을 동일하게 맞추는 작업을 말한다.
파티션 개수가 동일하고 전략도 동일하다면 동일한 메시지 키를 가진 데이터가 동일한 태스크에 들어가는것을 보장하게 된다. 이를 통해 각 태스크는 KStream의 레코드와 KTable의 메시지 키가 동일한 경우 조인을 수행할 수 있다.
코파티셔닝이 되지 않은 토픽의 경우 이슈가 발생

위와 같이 파티션의 수가 다르거나, 혹은 파티셔닝 전략이 다르다면 TopologyException이 발생하게 된다. 문제는 토픽들이 코파티셔닝 되어있음을 보장할 수 없다는데 있다. KStream과 KTable을 사용하는 2개의 토픽 A, B가 파티션 개수가 다를 수도 있고 파티션 전략이 다를 수도 있는 것이기 때문이다. 이런 경우 조인을 수행할 수 없고, 코파티셔닝 되지 않는 2개의 토픽을 조인하는 로직이 담긴 스트림즈 애플리케이션을 실행하면 TopologyException이 발생하게 된다.
GlobalKTable

KTable의 경우 파티션의 수만큼 태스크가 일대일 대응되어 처리했지만 GlobalKTable의 경우 모든 파티션을 모든 태스크에 전달하여 처리하게 하므로서 코파티셔닝 되지 않더라도 TopologyException이 발생하지 않게 된다.
단, 애플리케이션의 모든 태스크들이 토픽 내 모든 파티션의 데이터를 전부 가지면서 처리하게 되므로 데이터 양이 비대한 경우 용량에 무리가 있을 수 있으므로 KTable을 적절히 사용하는것이 필요하다.
스트림즈DSL 중요 옵션
bootstrap.servers (필수 옵션)
- "프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커의 호스트 이름:포트번호" 를 입력한다.
- 2개 이상의 브로커 정보를 입력하므로서 일부 브로커에 이슈가 생기더라도 접속에 이슈가 없도록 할 수 있다.
application.id (필수 옵션)
- 스트림즈 애플리케이션을 구분하기 위한 고유한 아이디이다.
- 다른 로직을 가진 스트림즈 애플리케이션이라면 서로 다른 아이디를 가져야 한다.
- 이 id를 가지고 컨슈머 그룹으로 지정하는데 사용하기도 한다.
default.key.serde (선택 옵션)
default.value.serde
- 메시지 키, 메시지 값을 직렬화, 역직렬화 하는 클래스를 지정한다.
- 기본값은 바이트 직렬화 & 역직렬화 클래스인 Serdes.ByteArray().getClass().getName()
num.stream.threads (선택 옵션)
- 스트림 프로세싱 실행 시 실행될 스레드의 개수를 지정한다. 멀티 스레드, 즉 멀티 태스크로 처리하고자 한다면 지정이 필요하다.
- 기본값은 1
state.dir
- 상태 기반 데이터 처리를 할 때 데이터를 저장할 디렉토리 경로를 지정한다.
- 파일 시스템으로 디스크에 저장되는 경로이다.
- 기본값은 /tmp/kafka-streams
'기술 학습 > 아파치 카프카' 카테고리의 다른 글
| 아파치 카프카 애플리케이션 프로그래밍 정리 8-2 _ 카프카 스트림즈 애플리케이션 (2) | 2023.07.24 |
|---|---|
| 아파치 카프카 애플리케이션 프로그래밍 정리 7 _ 멱등성 프로듀서 / 트랜잭션 프로듀서와 컨슈머 (0) | 2023.07.10 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 6-2 _ 카프카 컨슈머 애플리케이션 (0) | 2023.07.03 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 6-1 _ 카프카 컨슈머 (2) | 2023.06.26 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 5-2 _ 카프카 프로듀서 애플리케이션 (0) | 2023.06.19 |