1. 카프카 역사와 미래
프로듀서 -토픽 - 컨슈머 구조
- 토픽 내 여러 파티션이 존재하며, 프로듀싱은 하나의 파티션에만 쌓인다.
- 파티션은 큐 구조로 FIFO로 쌓이지만 컨슈밍하여도 제거되지 않는다.
- 읽은 위치는 commit으로 기록한다.
- 높은 처리량
- 프로듀서 → 브로커, 브로커 → 컨슈머로 데이터를 전송할 때 묶음 단위 전송으로 속도를 개선
- 여러 파티션에 분배하고, 파티션 수 만큼 컨슈머를 늘림으로서 병렬처리를 하여 시간당 데이터 처리량 개선 가능
- 확장성
- 특정 이벤트가 몇건 들어올 지 모를 때 가변적으로 대응할 수 있다
- 데이터를 저장하고 있는 곳이 브로커이며, 사용량이 적고 많은에 따라 브로커 scale-in/out이 가능
- 영속성
- 다른 메시징 플랫폼과 다르게 전송받은 데이터를 메모리가 아닌 파일 시스템에 저장
- Q. 느릴 수 있지 않나?
→ 운영체제 레벨에서 파일 I/O 성능 향상을 위한 페이지 캐시 영역을 메모리에 따로 생성해서 활용하여 최적화함 - 갑작스러운 오류로 인한 종료에도 안정적인 재시작 후 처리가 가능
- 고가용성
- 클러스터 내에 기본 3개 이상의 브로커를 갖는다. 이때 프로듀서로 부터 전송받은 데이터는 하나의 브로커가 아닌 모든 브로커에 복제되어 저장됨
람다 아키텍쳐
[데이터 인풋] ⇒ 배치 레이어 ➡️ 서빙 레이어 ⇒ [데이터 제공]
[데이터 인풋] ⇒ 스피드 레이어 ↗️
카파 아키텍쳐
[데이터 인풋] ⇒ 스피드 레이어 ➡️ 서빙 레이어 ⇒ [데이터 제공]
- 배치레이어를 제거하고 모든 데이터를 스피드 레이어에서 처리하는 구조.
- 카프카는 배치성 데이터 & 실시간성 데이터를 모두 모으는 역할
- → 모든 변환 기록 로그를 timestamp와 함께 기록 후 특정 기간을 묶음단위로 배치로 처리

- 모든 로그에 timestamp가 있기에 “1월1일 ~ 12월31일 신입생 목록 데이터 가져오기” 등 배치처리가 가능하다.
스트리밍 데이터 레이크
[데이터 인풋] ⇒ 배치 레이어 ⇒ [데이터 제공]
- 서빙 레이어도 제거된 구조
- 카프카에 분석과 프로세싱을 완료한 대용량 데이터를 오랜기간 저장 및 사용할 수 있다면 가능
- 다만, 카프카가 자주 사용되는 데이터, 자주 사용되지 않는 데이터 구분 능력 등 필요한 부분이 많다
- 이를 위해 카프카 클러스터 외 오브젝트 스토리지(자주 사용되지 않는 데이터 저장소) 구조 등을 개발 중 ing
2. 카프카 기본 개념 설명
브로커
- 카프카 클라이언트와 데이터를 주고받기 위한 주체이자, 데이터를 분산 저장하는 애플리케이션
- 브로커는 하나의 서버에 하나씩 존재하며 일반적으로 클러스터 내 기본 3개이상 존재한다.
- 프로듀싱 되는 데이터가 복제되어 모든 브로커에 저장되므로 고가용성이 높다.

브로커 역할
컨트롤러
- 클러스터 내 n개의 브로커 중 1개가 해당 역할을 수행한다.
- 다른 브로커들의 상태를 체크, 빠지는 경우를 확인해서 해당 브로커 내 리더_파티션을 재분배한다.
- 컨트롤러 브로커에 장애가 생기면 다른 브로커가 대신 수행한다.
데이터 삭제
- 컨슈머가 데이터를 가져가도 토픽 내 데이터는 삭제되지 않는다. 이는 브로커만이 삭제가 가능하다 (컨슈머, 프로듀서도 요청 x)
- 삭제는 파일단위며, 단위 명은 “로그 세그먼트”이다. 로그 세그먼트에 다수의 데이터가 들어있으므로 선별적으로 데이터를 삭제할수가 없다
- 삭제는 시간마다, 특정 용량마다 등으로 설정 가능
컨슈머 오프셋
- 컨슈머가 토픽 내 몇번째 오프셋까지 읽었는지 체크하기 위해 “커밋”을 한다. 이 커밋을 저장한다. (네이밍: __consumer_offsets)
그룹 코디네이터
- 파티션은 컨슈머와 1:1 매핑 된다. 이때 특정 컨슈머에 오류가 발생하면 하나의 컨슈머가 해당 파티션을 읽게 되는데, 이처럼 파티션을 컨슈머로 재할당 하는 “리밸런스” 과정을 담당한다.
데이터 저장
- 파일 시스템으로 저장하며, “{토픽이름}.kafka-{파티션번호}” 의 규칙으로 kafka-logs 하위 디렉토리로 생성 후 파일이 저장된다.
클러스터
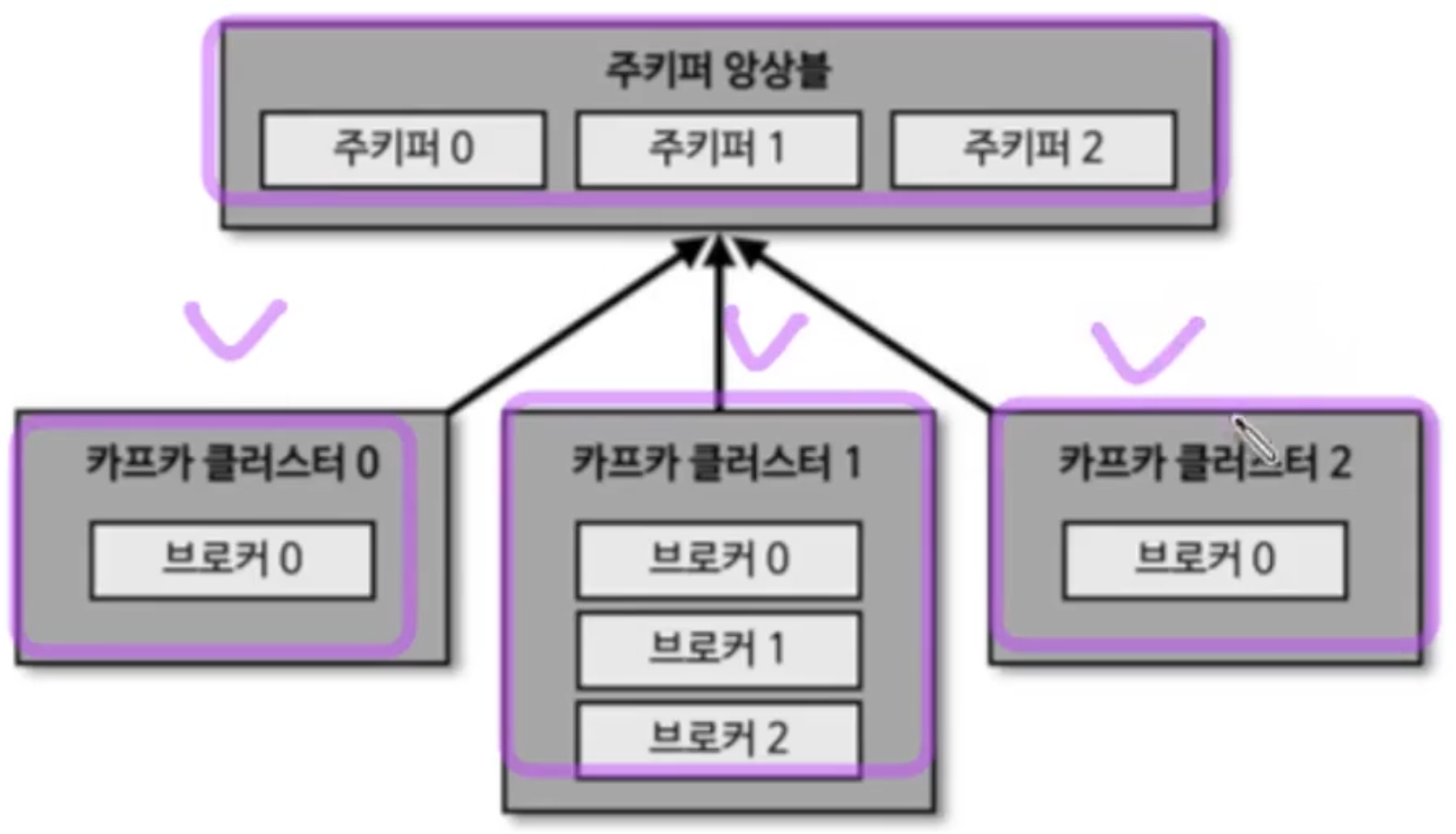
예시로 하나의 주키퍼로, 주문, 결제, 고객 팀 별 클러스터를 관리가 가능하다
- 여러대를 동시에 운용하기도 한다.
- root znode에 각 클러스터 별 znode를 생성 후, 클러스터 실행 시 root가 아닌 하위 znode에 지정
로그와 세그먼트

- log.segment.bytes: 브로커가 삭제할 수 있는 단위가 로그 세그먼트인데 이것의 크기를 결정. 바이트 단위의 최대 세그먼트 크기를 지정. 기본값은 1gb이다.
(7일이 안되도 용량에 도달하면 넘어감) - log.roll.ms (hours): 세그먼트가 신규 생성된 후 다음 파일로 넘어가는 시간 주기를 지정. 기본값은 7일 (1gb가 안되도 이 주기에 도달하면 넘어감)
로그와 세그먼트 역할
액티브 세그먼트
- 현재 쓰기가 일어나고 있는 파일을 지칭하는 용어. 이 파일은 브로커의 삭제대상에 포함되지 않는다.
- 액티브가 아닌 일반 세그먼트는 리텐션 기간 이후에 따라 삭제될 수 있다.
세그먼트와 삭제주기
- retention.ms(minutes, hours)로 리텐션을 조절한다. 세그먼트를 보유할 최대 기간이다.
- retention.bytes: 파티션 당 로그 적재 바이트 값으로 기본값은 -1이다. (지정하지 않음)
- 데이터 통신량이 많은 토픽의 경우 파티션에 너무 많은 로그가 적재되지 않도록 주의해야한다!
- log.retention.check.interval.ms: 세그먼트가 삭제 영역(리텐션을 벗어난 추가 로그_세그먼트)에 들어왔는지 확안하는 간격이다.
- 기본 5분
세그먼트의 삭제(cleanup.policy=delete)

- 삭제는 log.segment 내 오프셋(레코드) 단위가 아니라, log.segment단위이다.
- 쌓인 레코드는 수정이 불가능하다. → consumer가 잘 사용할 수 있는 데이터인지 validation이 잘 이뤄져야한다.
세그먼트의 삭제(cleanup.policy=compact)

- 액티브 세그먼트를 제외한 나머지 세그먼트를 최신순 부터 메시지 key를 기준으로 최신 record만 남기고 삭제하는 삭제이다.
(실상 압축이다) - K3 key를 갖는 offset 중 latest는 16번이므로 이외 offset은 모두 제거한다. (액티브를 제외한 전 세그먼트에 대해 이뤄진다)
Q. 그럼 용도가 뭘까?
A. batch를 위한 작업으로 Materialized Views를 제공하기 위해 out of date 된 데이터는 필요가 없을 때 사용된다. 즉, 최신의 key만 가지고 구체화된 뷰를 제공하는데 매우 용이하다.
테일/헤드 영역, 클린/더티 로그
- 액티브를 제외하고, compact가 수행되어 압축된 레코드들을 클린 로그라고 부르며, 중복된 메시지 키가 없게 된다. 이러한 레코드들로 이뤄진 세그먼트는 테일 영역이 된다.
- compact가 아직 수행되지 않은 레코드들을 더티 로그라고 부르며, 이 세그먼트는 헤드 영역이 된다. 중복된 키가 존재한다
min.cleanable.dirty.ratio
cleanup.policy=compact가 수행되는 것은 이 옵션값에 따른다.
액티브 세그먼트를 제외한 일반 세그먼트들에 대해서 tail section 내 레코드 개수 vs head section 내 레코드 개수의 비교를 의미한다.
- 예를들어 9:1 이면 head section의 dirty log 수가 90%, tail section의 clean log가 10% 일 때 compact가 수행되는 것이다. 모았다가 처리하므로 압축 효율이 좋고, 브로커도 가끔 압축을 수행하므로 부담이 적다. 하지만 최신 데이터 유지가 안되고, 용량의 부담이 있다. 반면에 1:9면 반대인데, 10%의 dirty log와 90%의 tail section이므로 용량 관리가 좋고 데이터 최신화가 잘되지만, 자주 압축을 수행해야 하므로 브로커에 부담이되며 압축 시 효율도 떨어진다.
복제 (replication)
- replication이 3이라면 3배의 용량 만큼 저장된다.
- 동일한 내용이 각 브로커에 저장된다.

- 파리션의 리더 == 리더 파티션
- 파티션의 팔로워 == 팔로워 파티션
컨슈머는 팔로워가 아닌 리더 파티션과만 통신을 진행하게 된다. 다만 리더 파티션이 브로커가 다운되었을 때 다른 브로커를 리더를 승급 시켜서 이어서 통신을 할 수 있게 한다.
ISR (In-Sync-Replicas)

리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태를 뜻한다. 이것은 리더 브로커가 다운되었을 때 팔로워 파티션을 리더로 승급할 지 여부를 결정할 때 중요한 역할을 한다.
ISR이 되어있지 않다면 리더와 팔로워 간 데이터에 불일치가 있다는 의미이다.
unclean.leader.election.enable=true: 유실을 감수하고 복제가 안된 팔로워 파티션을 리더로 승급한다.
unclean.leader.election.enable=false: 유실을 감수하지 않고, 리더 파티션이 복구될 때까지 중단한다.
- 토픽 별로 설정이 가능하므로, 중요도에 따라 처리하면 좋다.
토픽, 파티션
토픽과 파티션

- 파티션에 Queue형태로 쌓이게 된다. 이때 큐에 쌓인 데이터를 제거하지 않으므로 하나의 데이터를 여러 외부 프로그램이 접근하여 사용할 수 있다.
토픽 생성 시 파티션이 배치되는 방법

파티션이 5인 토픽을 생성했을 때, 파티션은 0번 브로커부터 라운드 로빈 방식으로 리더 파티션이 생성되게 된다. 카프카 클라이언트는 리더 파티션과만 통신한다고 했으므로 이를 통해 특정 브로커에만 통신이 집중되는 핫스팟 현상을 막을 수 있다. 데이터가 많아져서 브로커가 추가되는 scale-out이 발생해도 자연스럽게 파티션을 배분하여 대응이 가능하다.

위 그림처럼 여러 브로커에 리더 파티션이 분포되게 된다.
리더 파티션이 특정 브로커에 쏠리는 현상

위와 같은 특정 브로커에 파티션이 몰리는 현상이 발생할 수 있다. 이럴 때는 kafka-reassign-partitions.sh 명령을 통해 파티션 재분배가 가능하다.
파티션 개수 줄이기
파티션은 "데이터_세그먼트" 단위로 데이터를 파일로 저장하고 있으므로 파티션을 줄이기 위해선 모든 데이터를 취합한 후 정렬해야하는 과정이 필요하다. 하지만 이러한 기능자체를 지원하지 않는다. (따라서, 파티션을 늘릴때는 주의하자)
레코드

- 파티션에 쌓이는 레코드이다.
- 프로듀서가 생성한 레코드가 브로커로 전송되면 오프셋과 타임스탬프가 지정되어 저장된다.
- 한번 적재된 레코드는 수정이 불가하며, 로그 리텐션 기간 or 용량에 따라서 처리된다.
타임스탬프
- 기본적으로 레코드가 생성된 시간이 설정된다.
- 브로커에 적재된 시간으로 설정할 수도 있다.
오프셋
- 프로듀서가 생성한 시점의 레코드에는 존재하지 않는다. 프로듀서가 전송한 레코드가 브로커에 적재될 때 오프셋이 지정된다.
헤더
- http header같은 메타데이터를 담는 용도
메시지 키(key)
- 메시지 값의 분류하기 위한 용도로 사용된다. 이를 파티셔닝이라고 일컫는다.
- 파티셔닝에 사용되는 메시지 키는 파티셔너(Partitioner)에 따라 토픽의 파티션 번호가 정해진다.
- 메시지 키가 null일 경우 특정 토픽의 파티션에 라운드 로빈으로 전달된다. 그렇지 않다면 해시값에 의해 특정 파티션에만 쌓이게된다. (동일 키 ⇒ 동일 파티션)
메시지 값(value)
- csv, json, object 등이 담긴다.
- 사용자 지정 포맷으로 직렬화/역직렬화 클래스를 만들어서 사용할 수 있다. 다만, 메시지 값을 봐서는 어떤 포맷으로 직렬화되어 저장된건지 알 수 없으므로 컨슈머에서 사용할 역직렬화 포맷을 알고 있어야 한다.
- 보통 string으로 한다. (따라서, 숫자측면에서 공간낭비가 있음)
클라이언트 메타데이터
카프카 클라이언트는 리더 파티션과만 통신을 하는데 해당 리더 파티션이 어느 브로커에 위치하는지 알아야 한다. 따라서 데이터 통신 이전에 메타데이터를 브로커로부터 전달받아서 리더 파티션이 어느 브로커에 있는지 확인한다.
- 메타데이터 옵션
- metadata.max.age.ms: 메타데이터를 강제로 리프래쉬하는 간격, 기본값 5분
- metadata.max.idle.ms: 프로듀서가 유휴상태일 경우 메타데이터를 캐시에 유지하는 기간.
메타데이터 이슈가 발생하는 경우
- 카프카 클러스터는 반드시 리더 파티션과 통신을 해야한다.
- 만약 메타데이터가 현재의 파티션 상태에 맞게 리프레시 되지 않는 상태에서 잘못된 브로커에 통신을 하게 되면 LEADER_NOT_AVAILABLE exception이 발생하게 된다.
- 메타데이터로부터 전달 받은 리더 파티션의 브로커 위치에 대한 오류는 대부분 메타데이터 리프래쉬 이슈로 발생되므로 리프래쉬 간격을 조절하도록 하자.
'기술 학습 > 아파치 카프카' 카테고리의 다른 글
| 아파치 카프카 애플리케이션 프로그래밍 정리 6-2 _ 카프카 컨슈머 애플리케이션 (0) | 2023.07.03 |
|---|---|
| 아파치 카프카 애플리케이션 프로그래밍 정리 6-1 _ 카프카 컨슈머 (2) | 2023.06.26 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 5-2 _ 카프카 프로듀서 애플리케이션 (0) | 2023.06.19 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 5-1 _ 카프카 프로듀서 (1) | 2023.06.12 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 4 _ 카프카 CLI 활용 (0) | 2023.06.05 |