카프카 CLI tool
토픽 관련 명령을 실행할 때 필수 옵션과 선택옵션이 존재한다. 해당 값들이 어떻게 설정되어있는지, 어떻게 설정할지 확인 후 CLI 툴을 사용하자.
zookeeper-server.start.sh / kafka-server-start.sh



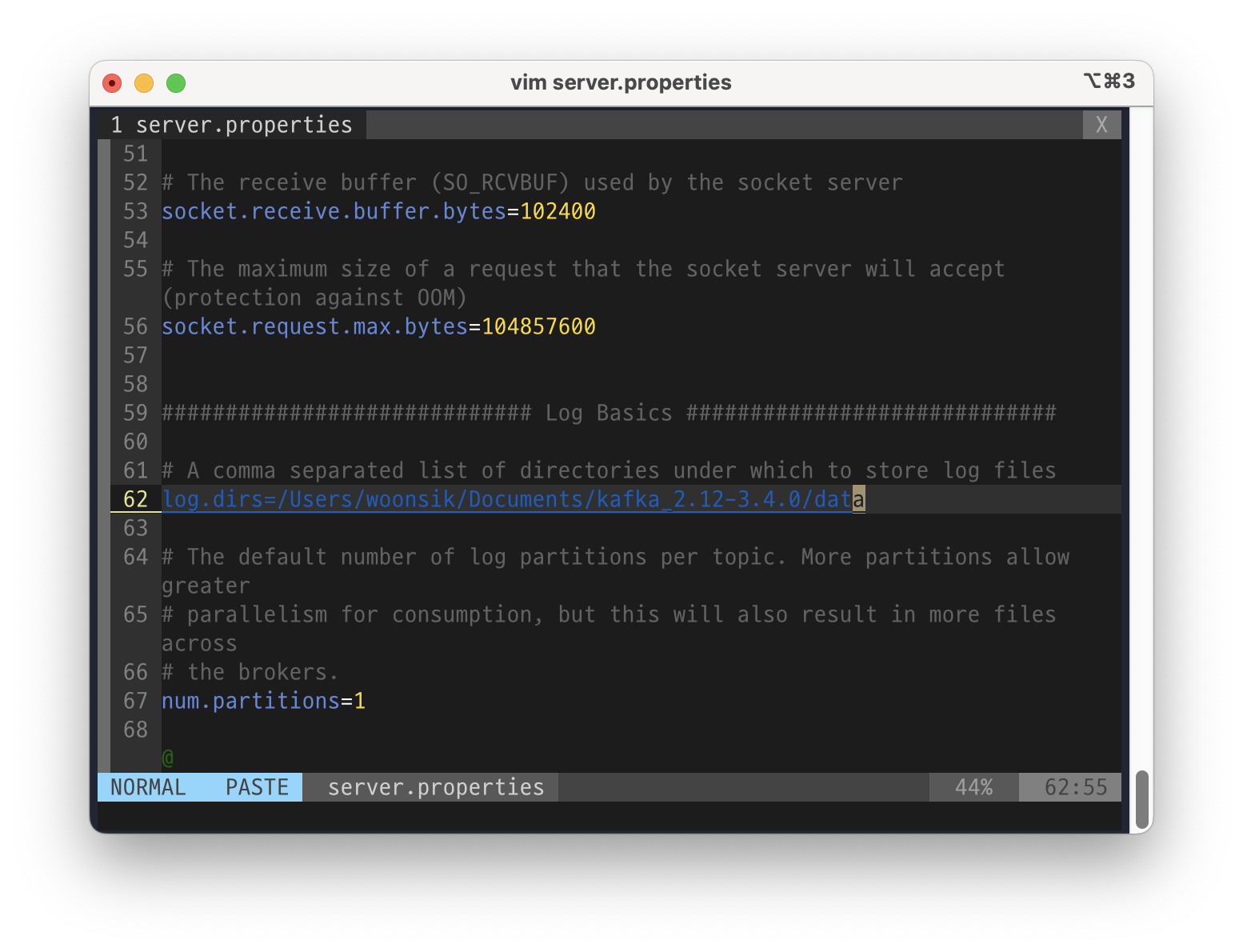
카프카 실행을 로컬에서 진행할 것이므로 로컬 통신을 위한 호스트를 지정해주자.

로그와 인덱스 등의 파일을 저장하기 위한 위치도 지정해준다.
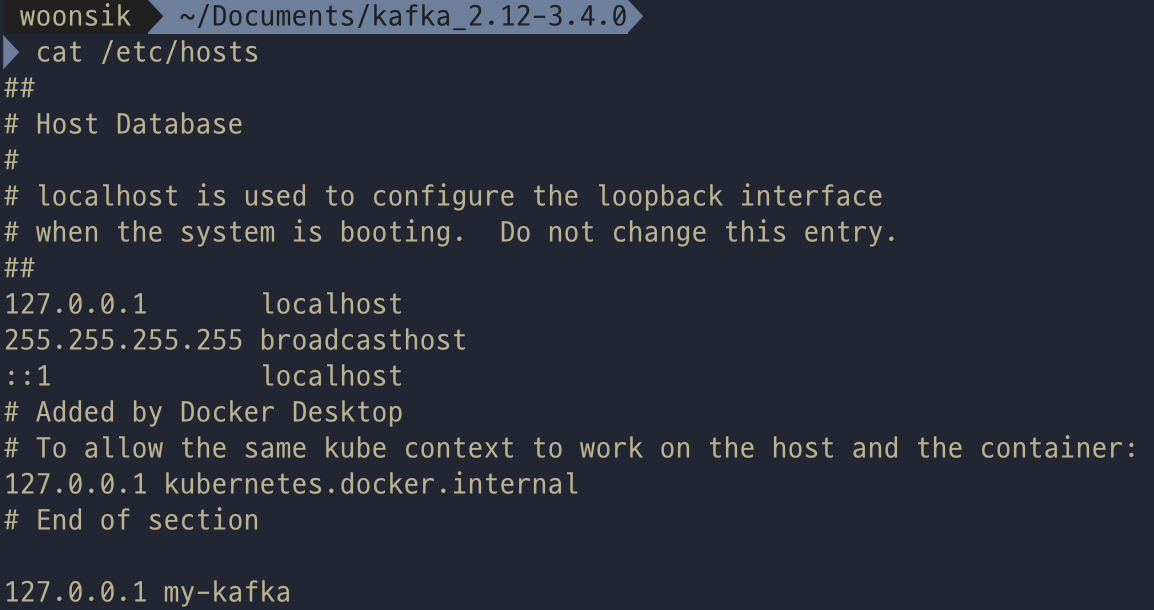
etc/hosts 파일에 localhost 주소에 대한 "my-kafka"라는 별칭을 추가해준다.
kafka-topics.sh
카프카 토픽에 대해 CLI를 진행해보자. kafka-topcis.sh를 통해 토픽 생성이 가능하다. 카프카 토픽을 생성 시 디폴트 값으로 설정된 것을 확인해 볼 수 있다.

다음과 같이 처음부터 설정값을 함께 입력하여 생성도 가능하다.


이미 만들어진 토픽에 대해서도 "--alter" 옵션을 추가하여 partitions의 개수를 변경할 수 있다.
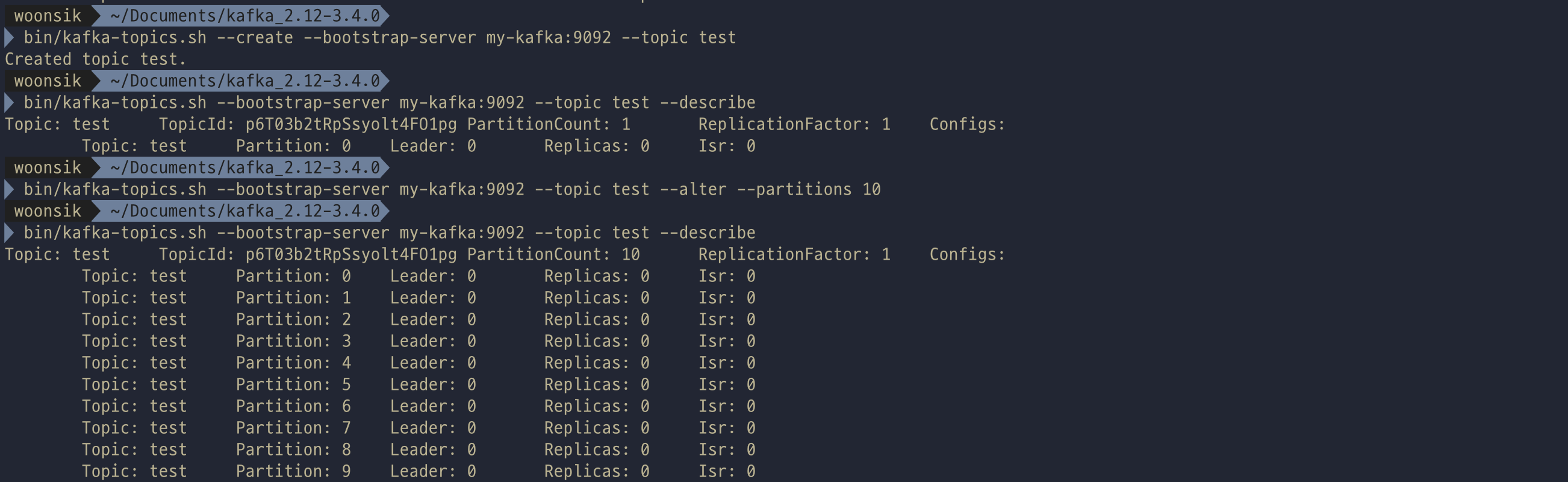
이때 주의할 점으로 이미 늘린 파티션을 줄이는것은 불가능하다! 아래처럼 파티션을 줄이도록 명령어를 입력 시 오류가 발생하는 것을 확인할 수 있다.

kafka-console-producer.sh
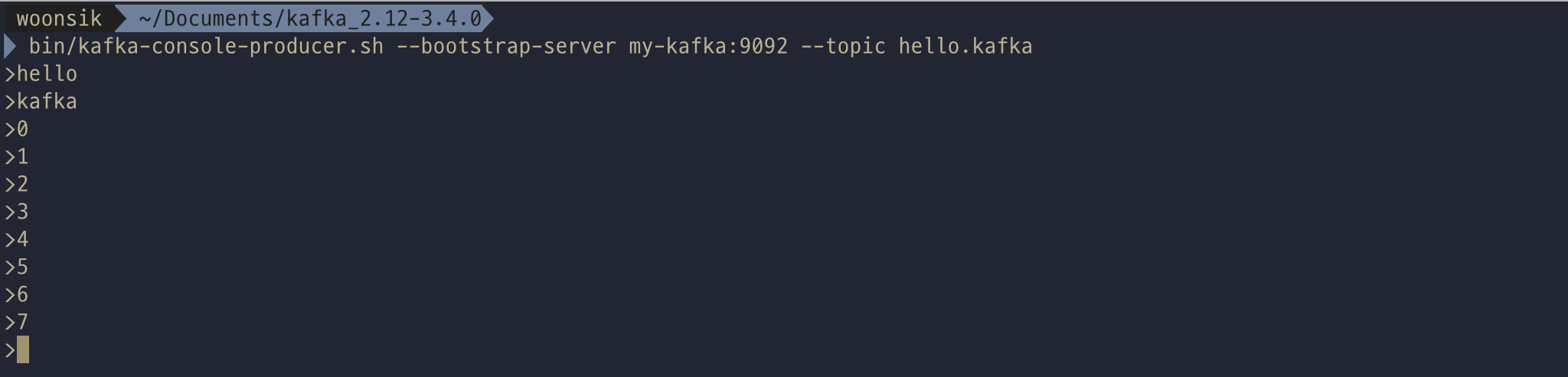
"kafka-console-producer.sh"를 이용하여 특정 카프카 토픽에 데이터를 넣을 수 있는 명령어를 실행할 수 있다. 키보드로 문자를 작성하고 엔터키만 누르면 별다른 응답 없이 메시지 값이 전달된다.
메시지 키를 가지는 레코드를 전송하기 위해서는 추가 옵션을 작성해야한다. key.separator 를 선언하지 않으면 기본 설정은 (tap, \t)이므로 key.separator를 선언하지 않고 보내려면 메시지 키(탭)메시지 값을 작성하고 엔터를 누르면 된다. 메시지 키가 없다면(null)이다.
파티션에 대해 round-robin 방식으로 레코드가 쌓이게 된다. 메시지 키를 설정하면 특정 파티션에 쌓이게 되는데 이를 통해 얻을 수 있는 점은 순서대로 데이터를 쌓을 수 있다는 점이다. 컨슈머는 해당 파티션에서 특정 메시지키의 메시지값을 읽어서 처리할 때 순서대로 처리할 수 있게 된다.
디폴트는 라운드 로빈방식으로 쌓이게된다.

--property 명령어를 통해 메시지키 설정여부와 구분자를 설정해주면 메시지키{구분자}메시지값 형태로 보낼 수 있다.
kafka-console-consumer.sh
topic으로 전송한 데이터를 조회하기 위한 용도로 사용된다. --from-beginning 옵션을 주면 토픽의 처음 메시지부터 출력해준다.
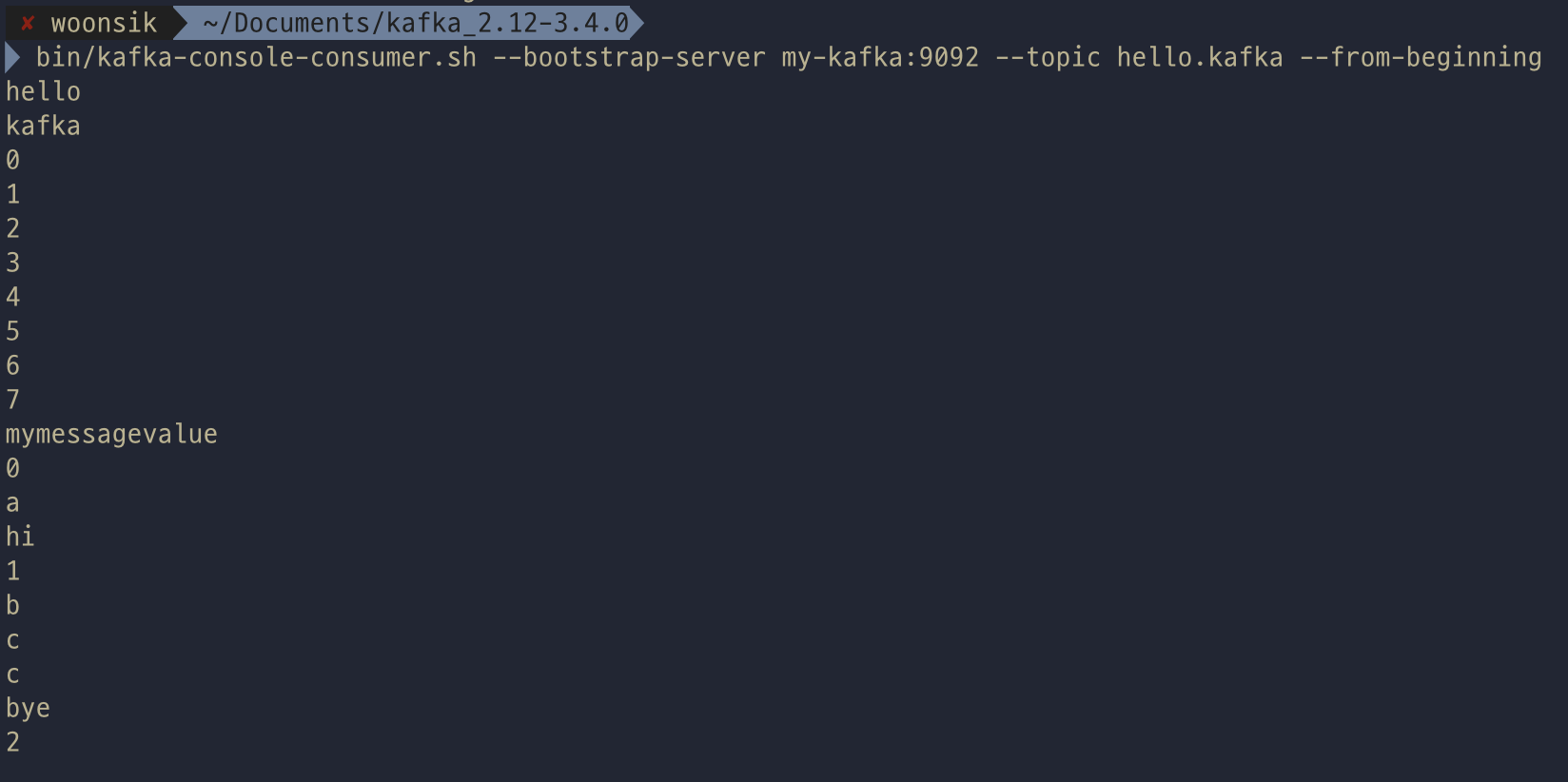
--property print.key, --property key.separator 를 사용하여 키와 값을 구분자와 함께 출력할 수 있다.

실사용 카프카의 경우 실시간으로 데이터가 계속 프로듀싱 되어 컨슈밍 된 데이터가 출력될 수 있다. 이때 --max-messages 를 사용하면 해당 수만큼의 데이터만 보여주게 된다.

특정 파티션에 들어있는 메시지만 컨슘하고 싶다면 --partition {number} 명령어를 사용하면 된다.

--group {그룹명}
- 특정 토픽에 대해 읽은 메시지에 대해 커밋을 함으로서 어디까지 읽었는지 기록할 수 있다.
- 읽기를 수행하면 이전에 마지막으로 읽었던 메시지 다음부터 읽는다.

이미 읽은 부분은 빼고 그다음부터 출력되는것을 볼 수 있다.
kafka-consumer-groups.sh
- --describe 옵션을 사용하면 해당 컨슈머 그룹이 어떤 토픽을 대상으로 레코드를 가져갔는지 상태를 확인할 수 있다.
- 파티션 번호, 현재까지 가져간 레코드의 오프셋, 파티션 마지막 레코드의 오프셋, 컨슈머 랙, 컨슈머 ID, 호스트를 알 수 있다.
- 컨슈머 랙은 지연의 정도를 나타낸다. 프로듀서에 비해 컨슈머의 동기화 지연 여부를 알 수 있다.


--reset-offsets
- 오프셋을 리셋하여 특정 오프셋부터 다시 읽을 수 있게하는 옵션

- hello.kafka 토픽에 대해 hello-group이 읽을 오프셋을 --to-earliest(가장 빠른것)으로 --reset-offsets 오프셋을 초기화하게된다.
초기화하는 오프셋 옵션 종류
- --to-earliest : 가장 빠른 오프셋
- --to-latest: 가장 늦은 오프셋
- --to-current: 현재 시점 기준 오프셋
- --to-datetime {YYYY-MM-DDTHH:mmSS.sss}: (레코드 타임스탬프 기준) 특정 일시의 오프셋
- --to-offset {long}: 특정 오프셋
- --shift-by {+/-long}: 현재 기준 앞뒤 오프셋
위 옵션으로 설정한 오프셋으로 초기화된다. 만약 현재 오프셋이 1인데 10억건의 데이터가 쌓인 경우 9억9999만… 건의 모든 레코드를 처리할 것인지 버리고 10억번째 오프셋부터 처리할 것인지 결정할 때 리셋을 사용할 수 있다.
오프셋 이동 테스트
- 1. 카프카 프로듀싱으로 데이터를 쌓는다.

- 2. --describe로 오프셋을 확인.
- 이전에 확인한 (LOG-END-OFFSET)마지막 오프셋 값이 28에서 42로 14개의 레코드가 추가된것을 확인할 수 있다. 처리되지 않고 쌓인 LAG도 증가함을 확인할 수 있다.

- 3. 컨슈밍

- 컨슈밍 시 읽지 않은 모든 모든 데이터를 컨슈밍하는것을 확인할 수 있다.

상태를 확인하면 현재 오프셋이 마지막 오프셋으로 이동하고 랙도 전부 빠진것을 확인할 수 있다.
- 4. 오프셋을 다시 특정 오프셋으로 리셋

- hello-group이 hello.kafka토픽에 대한 오프셋을 35로 초기화한다. 그룹의 상태를 확인해보면 현재 오프셋이 35로 변경되고 랙도 다시 증가한 것을 확인할 수 있다.
kafka-producer/consumer-perf-test.sh
- 퍼포먼스 테스트를 위해 사용된다.
kafka-reassign-partitions.sh
- 리더파티션과 팔로워 파티션의 위치를 변경할 수 있다. 브로커 내 리더파티션의 핫스팟 이슈를 해결하기 위해 사용된다. 컨슈머는 리더파티션과만 통신을하므로 한 브로커에만 리더파티션이 쏠리는 현상을 막기 위해서이다.
kafka-delete-record.sh
- 레코드를 지우기 위해 사용된다.
'기술 학습 > 아파치 카프카' 카테고리의 다른 글
| 아파치 카프카 애플리케이션 프로그래밍 정리 6-2 _ 카프카 컨슈머 애플리케이션 (0) | 2023.07.03 |
|---|---|
| 아파치 카프카 애플리케이션 프로그래밍 정리 6-1 _ 카프카 컨슈머 (2) | 2023.06.26 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 5-2 _ 카프카 프로듀서 애플리케이션 (0) | 2023.06.19 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 5-1 _ 카프카 프로듀서 (1) | 2023.06.12 |
| 아파치 카프카 애플리케이션 프로그래밍 정리 1, 2 - 배경 및 기본개념 (0) | 2023.05.29 |